Do you feel like a spy? No worries, you’re in a good place to explore Confidential Computing and Confidential Nodes in Google Kubernetes Engine (which from now on I'll refer to as GKE). I’ll start from the basics of Confidential Computing and will explain why companies need Confidential Computing resources.
Last week, Google announced that Confidential GKE nodes are now available to the public.
With Confidential GKE Nodes, you can achieve encryption in-use for data processed inside your GKE cluster without significant performance degradation.
Before going deeper into Confidential Nodes in GKE, let’s start with Confidential Computing in general.
What is Confidential Computing?
Confidential computing is a cloud computing technology that isolates sensitive data in a protected CPU enclave during processing. The contents of the enclave — the data being processed, and the techniques that are used to process it — are accessible only to authorised programming code, and are invisible and unknowable to anything or anyone else, including the cloud provider.
For years, cloud providers have offered encryption services to help protect data at rest (in storage and databases) and data in transit (moving over a network connection). Confidential computing eliminates the remaining data security vulnerability by protecting data in use — that is, during processing or runtime.[1]
How does Confidential Computing work?
Before it can be processed by an application, data must be unencrypted in memory. This leaves the data vulnerable just before, during, and just after processing to memory dumps, root user compromises, and other malicious exploits.
Confidential computing solves this problem by leveraging a hardware-based trusted execution environment, or TEE, which is a secure enclave within a CPU. The TEE is secured using embedded encryption keys; embedded attestation mechanisms ensure that the keys are accessible to authorised application code only. If malware or other unauthorised code attempts to access the keys — or if the authorised code is hacked or altered in any way — the TEE denies access to the keys and cancels the computation.
In this way, sensitive data can remain protected in memory until the application tells the TEE to decrypt it for processing. While the data is decrypted and throughout the entire computation process, it is invisible to the operating system (or hypervisor in a virtual machine), to other compute stack resources, and to the cloud provider and its employees.[2]
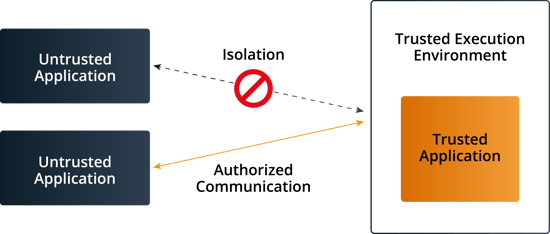
How Confidential Computing works
The Confidential Computing Consortium
If you’re wondering how the idea of Confidential Computing came about, here is a brief explanation of how it started. In 2019, a group of IT enterprises composed of Alibaba, AMD, Baidu, Fortanix, Google, IBM/Red Hat, Intel, Microsoft, Oracle, Swisscom, Tencent, and VMware announced the creation of the Confidential Computing Consortium (CCC), under the sponsor of The Linux Foundation. The CCC aims to promote the development of open-source CC tools and define general standards for Confidential Computing, which allow users to move between different IT environments with ease.
How does data leak from the CPU?
In 2018, two disastrous new processor vulnerabilities called Spectre and Meltdown occurred.
Spectre and Meltdown individually represent classes of hardware vulnerabilities, each with a number of variants dependent on specific silicon-level functionality. Differences between manufacturers (e.g., Intel vs. AMD) and architectures (e.g., x86-64 vs. Arm) make some processors vulnerable to more variants than others.
What are Spectre and Meltdown?
Spectre and Meltdown enable attackers to extract encryption keys and passwords from compromised systems, enabling other attacks dependent on access to compromised systems.
For cloud computing, Spectre and Meltdown can be leveraged by attackers to escape software containers, para-virtualized systems, and virtual machines.
The exploitation of Spectre and Meltdown can be performed untraceable, without leaving evidence of an exploit in system logs.[3]
How do Spectre and Meltdown work?
Spectre, according to the original authors of the Spectre paper, “[induces] a victim to speculatively perform operations that would not occur during strictly serialized in-order processing of the program’s instructions, and which leak victim’s confidential information via a covert channel to the adversary.”
Spectre attacks are conducted in three steps:
- The setup phase, in which the processor is mistrained to make “an exploitably erroneous speculative prediction.”
- The processor speculatively executes instructions from the target context into a microarchitectural covert channel.
- The sensitive data is recovered. This can be done by timing access to memory addresses in the CPU cache.
Meltdown exploits a race condition between memory access and privilege level checking while an instruction is being processed.
Meltdown attacks, according to the original authors of the Meltdown paper, are conducted in three steps:
- The content of an attacker-chosen memory location, which is inaccessible to the attacker, is loaded into a register.
- A transient instruction accesses a cache line based on the secret content of the register.
- The attacker uses Flush+Reload to determine the accessed cache line and hence the secret stored at the chosen memory location.
Why use Confidential Computing?
Confidential Computing offers numerous benefits to organisations; the following is a list of the main ones:
- Protect sensitive data during processing: Using Confidential Computing along with encryption at rest and transmit will help organisations to achieve their goals of handling sensitive and regulated data.
- Protect the organisation's intellectual property: Confidential Computing is not only for data protection. Confidential computing can help to execute application code secretly in an isolated environment that no one can infiltrate.
- To eliminate concerns when choosing cloud providers: An organisation can select the best cloud provider that meets its technical and business objectives without worrying about the security of stored data.
- Enable complete end-to-end encryption of cloud data.
- It allows data to be transferred between different environments, or cloud providers, without the risk of exposing it to unauthorised parties.
- To collaborate securely with partners on new cloud solutions: For example, one company's team can combine its sensitive data with another company's proprietary machine-learning algorithm to create new solutions without sharing any data or intellectual property that it doesn’t want to share.
What are GKE Confidential Nodes?
With Confidential GKE Nodes, you can achieve encryption in-use for data processed inside your GKE cluster without significant performance degradation.
Built on Confidential VMs, which utilize the AMD Secure Encrypted Virtualization (SEV) [4] feature.
Confidential GKE Nodes encrypt the memory of your nodes and the workloads that run on top of them with a dedicated per-Node instance key that is generated and managed by the AMD Secure Processors, which is embedded in the AMD EPYC™ processor[5]. These keys are generated by the AMD Secure Processor during node creation and reside solely within it, making them unavailable to Google or any VMs running on the host. This, combined with other existing solutions for encryption at rest and in transit, and workload isolation models such as GKE Sandbox, provides an even deeper and multi-layer defence-in-depth protection against data exfiltration attacks. Confidential GKE Nodes also leverage Shielded GKE nodes to offer protection against rootkit and bootkits, helping to ensure the integrity of the operating system you run on your Confidential GKE Nodes.[6]
Pricing
There is no additional cost to deploy Confidential GKE Nodes, other than the cost of Compute Engine Confidential VM.
Hands-on
Creating a GKE cluster that uses Confidential GKE Nodes on all nodes is easy. Simply go to the Cloud Console, click Kubernetes Engine, and then click Clusters. Select “Create” and then “Configure” on GKE Standard. Under Cluster, there is a security section where you click the checkbox that says “Enable Confidential GKE Nodes.”
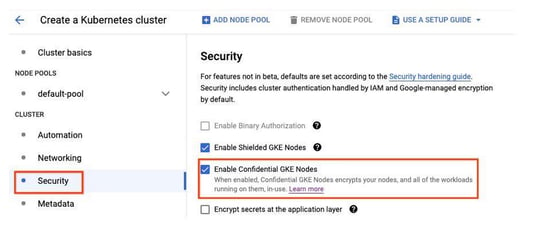 Enabling Confidential GKE Nodes
Enabling Confidential GKE Nodes
Enable Confidential Nodes via Gcloud
When creating a new cluster, just specify the --enable-confidential-nodes option in the gcloud CLI:
|
gcloud container clusters create ${CLUSTER_NAME} \ |
Replace the following:
- CLUSTER_NAME: the name of your new cluster.
- N2D_MACHINE_TYPE: the machine type for your cluster's default node pool, which must be the N2D machine type.
Run applications on Confidential GKE Nodes
Google's approach to confidential computing is to enable an effortless lift and shift for existing applications. GKE workloads that you run today can run on Confidential GKE Nodes without code changes.
You have the option of declaring that your workloads must only run on clustered with Confidential GKE notes. You can do this using the cloud.google.com/gke-confidential-nodes node selector.
Here's an example Pod spec that uses this selector:
|
apiVersion: v1 |
Limitations
Confidential GKE Nodes have the following limitations:[7]
- Confidential GKE Nodes only support Persistent Volumes backed by persistent disks if your control plane runs GKE version 1.22 and later. For instructions, refer to Using the Compute Engine persistent disk CSI Driver.
- Confidential GKE Nodes are not compatible with GPUs.
- Confidential GKE Nodes are not compatible with sole tenant nodes.
- Confidential GKE Nodes only provide support using ephemeral storage on local SSDs and don’t provide support on local SSDs in general.
- Only Container-Optimized OS nodes are supported. Ubuntu and Windows nodes are not supported.
In this blog post, we deep-dived into Confidential Computing and Confidential Nodes in GKE.
I hope you found this post helpful, and if you enjoyed reading it, please don’t forget to share.