Introduction
Briefly, a Stateless Application implies that a process never stores a state/data that will be required on another request or transaction. The app can cache some data on the disk or in-memory but never relies on that cached data to be available on the next action. In Kubernetes, we use Deployment resources to manage Stateless Apps.
It's simple to run Stateless Apps on Kubernetes. With Kubernetes, we can release a new version and apply various deployment strategies. If needed, we can configure a HorizontalPodAutoscaler resource and scale-out the app based on the demand. We can delete a pod/workload and know that we don't lose any state/data (as the name suggests).
On the contrary, Stateful Applications store and manage data. When your data is lost or corrupted, it's very challenging, or in some cases, even impossible to fix. I’m aware of the concerns that most people have when managing Stateful Apps, so I’m twice as careful when taking actions on them. This blog post will share some of the best practices for running a Database properly on the Kubernetes production environment. It might seem challenging, but the Kubernetes community is making a big effort to make it easier. We'll implement these practices using the latest Kubernetes APIs, tools, and techniques.
Cloud Managed vs Self-Hosted Databases
This comparison is not the main topic of this post, but I think it’s important to understand the drawbacks of self-hosted databases. If you have a chance to use Cloud Provider Services, go for it. Self-hosting databases are challenging and require a lot of time compared to Cloud managed solutions. Features you need to maintain manually on self-hosted solutions will probably be a click-away in a cloud solution. Use this blog post to solve some edge cases and understand Statefulsets in Kubernetes in depth.
Statefulsets in Depth
Statefulset resource is the workload API used to run stateful applications on Kubernetes. It’s very similar to Deployment workload API and manages the Pods, but there are also some important criteria to manage stateful apps properly:
- Unique network identifiers (using Headless Service) which don’t change in a failure case
- Ordered, graceful deployment and scaling
- Ordered, automated rolling updates
- Each Pod has its own Persistent Volume. Even if a pod fails, PV will be attached to the same Pod.
We’ll access Pods using these network identifiers. Let’s think MongoDB replica set setup. We’ll use the Primary Node for the write operations and the Secondary Nodes for the read operations.
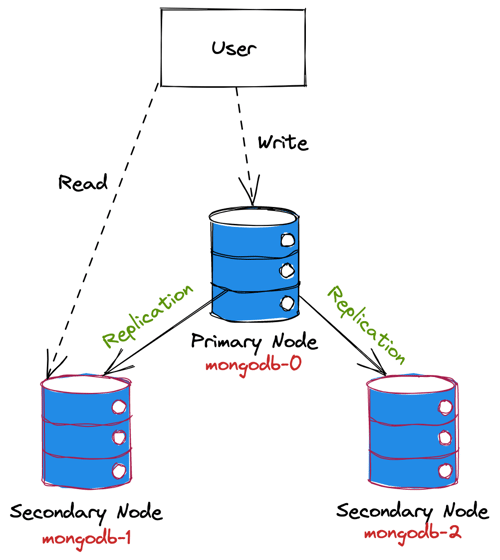
As you can see in the diagram, the user is sending write requests to mongodb-0 instance and sending read requests to mongodb-1. In this case, it’s important to know which pod will receive the request and Kubernetes is providing dedicated network identifiers to make that possible.
As a default, the Kubernetes Service resource provides a Load Balancing between the pods, but we don’t need it in that example. So, using Headless Service will be a suitable option to access pods directly using dedicated network identifiers.
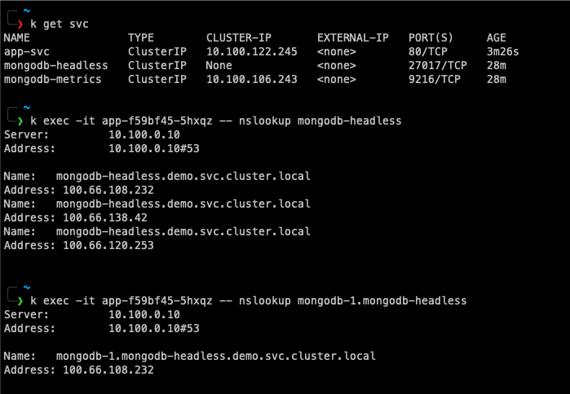
mongodb-headless is the headless service resource created for MongoDB Statefulset. When I run nslookup command using that service, it returns all of the pod IP addresses. If I also add the pod name, it’ll return the specific pod’s IP address.
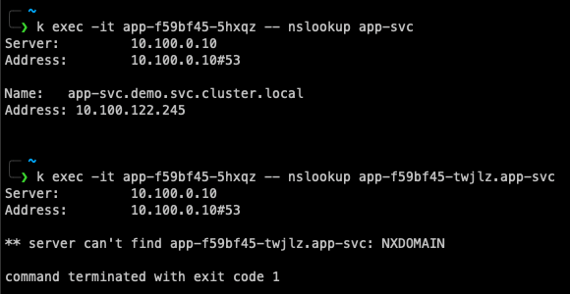
app-svc is a standard Service resource responsible for load balancing between the pods. You can’t use the pod name to access a specific IP address. It doesn’t work that way.
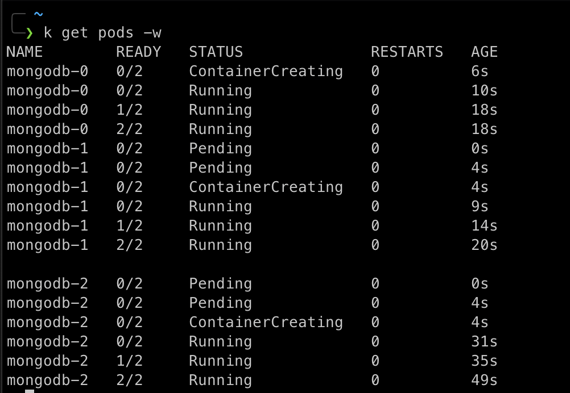
When the MongoDB Statefulset deployed, it was created in order starting with the smallest ordinal. However, If I apply a RollingUpdate, it will start from the largest ordinal which is mongodb-2.
Persistent Volume Management on Kubernetes
Now we have an overview of the Statefulset and its lifecycle. On Kubernetes, we have another essential component to run a database which is PersistentVolume. As you know, we need to provide storage to write our state into. We can provide and manage these storage options using different mechanisms.
As we use AWS in that post, we can ask how Kubernetes interact with AWS APIs and provide required storage options like EBS, and EFS? There are several cloud providers and volume options available. Each of them has its own implementation and lifecycle. This creates a challenging problem.
In the past, there were in-tree implementations that were integrated with Kubernetes core. There were code blocks inside of Kubernetes codebase to manage, for instance, AWS EBS volumes. When vendors wanted to add their storage system to Kubernetes, they had to deal with the Kubernetes release process. As you can see, it was not a scalable solution, so Kubernetes adopted Container Storage Interface(CSI). CSI is a standard for exposing arbitrary block and file storage systems to containerized workloads.
Vendors can implement their CSI Driver and users can install and start to use it immediately. With the power of CSI, the Kubernetes volume layer became truly extensible. In-tree volume plugin API will be deprecated in upcoming releases, so I recommend using CSI drivers natively.
Now we are aware that CSI will interact with vendors, but we still need to define the properties of storage we need. Kubernetes has PersistentVolumeClaims API to request volumes. PVCs also provide a binding between Pods and PersistentVolumes.
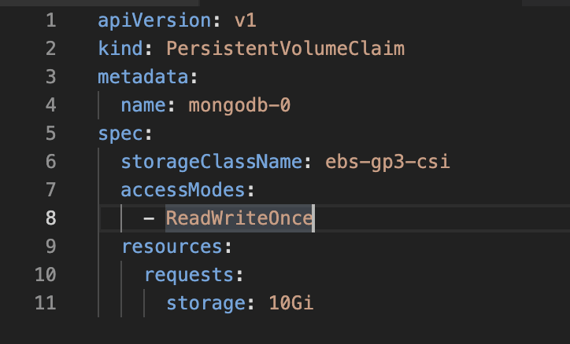
On MongoDB replica set design, each pod only has access to its own volume, so ReadWriteOnce access mode is suitable for this case. Additionally, PVC specifies the storage capacity needed by the application. These properties seem vendor agnostic, but how do we specify vendor-specific parameters? Kubernetes has another API for that which is StorageClass.
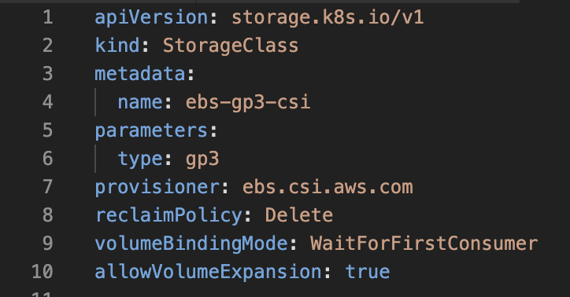
As you can see in our YAML example, StorageClass defines the AWS-specific parameters using parameters block. MongoDB will use EBS volumes, so we’re defining a StorageClass to provide EBS volumes dynamically when the pods request it. Now, let’s summarize the relationships between the resources.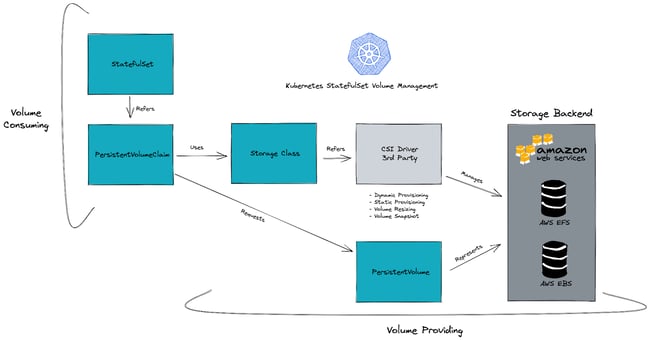
Statefulset refers to the PersistentVolumeClaim resource which binds volumes to the workloads. PVCs use StorageClass resources to create volumes dynamically using vendor-specific parameters. StorageClass refers to CSI driver and the CSI driver provides volumes by interacting with vendor APIs.
So far, I have explained the definitions, APIs, and the relationships between them. However, in the real world, we have a running system, and this system requires operations like Backup, Resizing, and Monitoring. Also, at some point, this running system might crash! How will we deal with database failure scenarios on Kubernetes? Stay tuned, I’ll explain everything in the next post!