Moving an LLM application from prototype to production requires more than selecting the right model.
In the early stages of an AI product, the architecture often looks simple. A product service sends a prompt to a model, receives a response and shows it to the user. For a proof of concept, that can be enough.
Production introduces a different set of requirements.
A single model call becomes part of a larger runtime path. Retrieval needs access control. Prompts need versioning. Inference needs routing. Token usage needs cost attribution. Responses need validation. Latency, cost and reliability need to be measured across the full request path, not only inside the model provider.
This is why production-ready LLM deployments should be designed as platform capabilities, not isolated feature integrations. For teams building a production-ready AI platform on AWS, the model is only one part of the operating model.
For SaaS, fintech, healthcare and AI-native product teams, this distinction matters. A working demo proves that a model can produce useful output. It does not prove that the system can operate reliably across tenants, users, workflows, data sources, cost limits and compliance boundaries.
This article looks at what engineering teams need to design before scaling LLM applications in production, including inference control, retrieval architecture, cost visibility, observability, governance and Generative AI and LLM deployment on AWS.
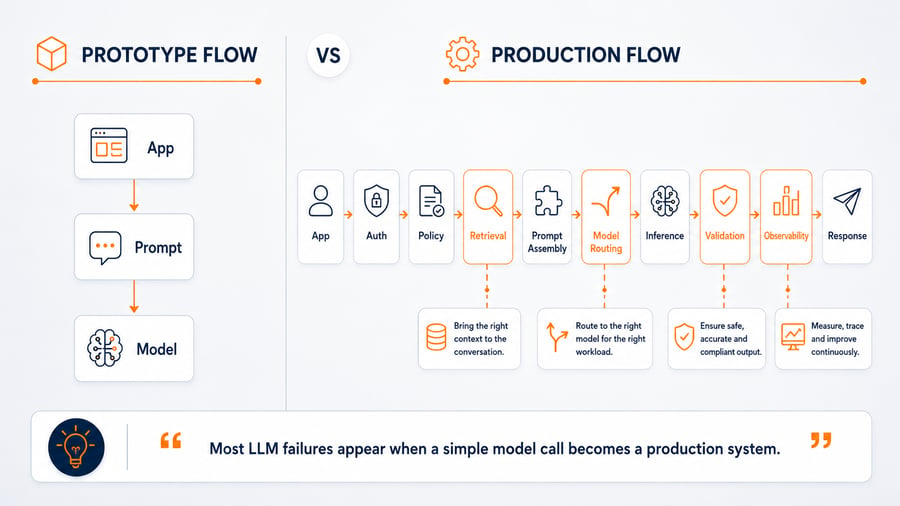
From Model Call to Production System
A prototype LLM flow often looks like this:
Application → Prompt → Model → ResponseA production LLM path is rarely that simple:
User request
→ Auth and tenant policy
→ Retrieval decision
→ Data access check
→ Search and re-ranking
→ Prompt assembly
→ Model route selection
→ Inference
→ Guardrail or validation
→ Logging and cost attribution
→ ResponseEvery step can introduce failure.
The problem is that many teams still operate the system as if it were only a model call.
That creates a gap between what the system actually does and what the engineering team can reliably observe, control and improve.
1. Model Access Spreads Across the Product
The first failure pattern is fragmented model access.
This usually starts naturally. One team adds a support assistant. Another team adds summarisation. Another builds an internal knowledge tool. Another experiments with a self-hosted model.
Soon, the platform has several model access paths:
-
one service calls Amazon Bedrock directly
-
another calls a third-party model API
-
another uses a self-hosted model on Kubernetes
-
another has its own retry logic
-
another logs prompts differently
-
another has no token budget
At that point, model access is no longer a feature-level decision. It has become a platform control problem.
The failure is not that teams use different models. We explored this operating model difference in more detail in Amazon Bedrock vs self-hosted LLMs.
The failure is that routing, policy, observability and cost control are scattered across the codebase.
What breaks
|
Area |
Production issue |
|---|---|
|
Governance |
Different workflows apply different rules |
|
Cost |
Token usage cannot be attributed clearly |
|
Reliability |
Retry and fallback behaviour varies by team |
|
Security |
Sensitive workflows may bypass stricter controls |
|
Observability |
Logs exist, but inference behaviour is not connected |
What works better
LLM access should be centralised through a controlled inference layer or AI gateway.
This layer creates a stable contract between product services and model providers. Product teams should not need to decide every detail of model execution.
The platform should control:
-
which model route is used
-
whether retrieval is required
-
which prompt version applies
-
what token budget is allowed
-
whether fallback is permitted
-
how the request is logged
-
where cost is attributed
Without this shared control layer, every new AI feature increases operational fragmentation.
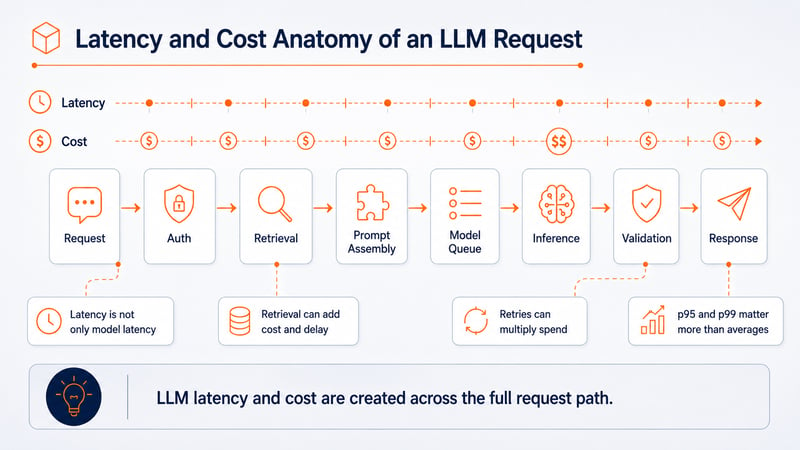
2. Latency and Cost Hide Inside the Request Path
When users say an AI feature is slow, teams often look first at the model.
But model latency is only one part of the experience.
A production LLM request may spend time in authentication, retrieval, metadata filtering, re-ranking, prompt assembly, model queueing, output generation, guardrails, validation and post-processing.
The model may be responding within an acceptable range, while the full product experience is still too slow.
For Amazon Bedrock workloads, teams should also track Amazon Bedrock runtime metrics such as invocation volume, invocation latency, input and output token consumption, throttles and error rates through CloudWatch, then connect those signals to application-level workflow latency.
The same applies to cost.
LLM cost is not created only by the model call. It grows across the request path:
|
Cost driver |
Why it grows |
|---|---|
|
Long prompts |
Too much instruction, context or history |
|
Over-retrieval |
Too many chunks added to the prompt |
|
Large outputs |
Responses are not bounded |
|
Retries |
Failed calls multiply token usage |
|
Fallbacks |
Expensive models are used too often |
|
Poor routing |
Simple tasks use high-cost inference paths |
For AWS-based deployments, understanding how tokens are counted in Amazon Bedrock is important because input tokens, output tokens, cache usage, request quotas and max output settings all affect cost and throttling behaviour.
This is why production teams need to measure latency and cost by workflow, tenant, route and task type.
The right question is not only:
How fast is the model?
It is:
Which part of the LLM request path is creating latency or cost?
Better production controls
|
Control |
What it prevents |
|---|---|
|
Token budgets by tenant |
One customer consuming uncontrolled spend |
|
Prompt and output limits |
Gradual prompt growth and verbose responses |
|
Selective retrieval |
RAG running when it is not needed |
|
Retry budgets |
Reliability logic multiplying cost |
|
Workload-based routing |
Simple tasks using expensive models |
Cost optimisation should be designed into the inference path, not added after the bill arrives. We covered this topic in more detail in reduce LLM inference costs on AWS.
3. RAG Is Treated as Search Instead of a Data System
Many production LLM failures are actually retrieval failures.
The model receives weak, outdated, incomplete or unauthorised context. The answer then looks like a model quality issue, but the root cause is upstream.
That is why RAG architecture on AWS should not be treated as a simple vector search feature.
In production, RAG needs operational control across:
-
document ingestion
-
chunking
-
metadata
-
embedding versions
-
index freshness
-
access control
-
hybrid search
-
re-ranking
-
citation quality
-
retrieval evaluation
The first version may work well because the dataset is small and clean. But production data changes. Documents are updated. Permissions change. New content types are added. Duplicates appear. Old embeddings remain in the index.
Over time, retrieval becomes less predictable.
That is how RAG systems fail in production.
Not because vector search does not work.
Because the retrieval layer is not operated as a production data system.
Common RAG failure modes
|
Failure mode |
Production impact |
|---|---|
|
Stale embeddings |
The model receives outdated context |
|
Weak metadata |
Filtering becomes unreliable |
|
Poor chunking |
Important information is split or buried |
|
Over-retrieval |
Prompts become long, expensive and noisy |
|
No permission-aware retrieval |
Sensitive data may be exposed |
|
No retrieval evaluation |
Teams cannot measure answer grounding |
RAG is not just a model feature. It is a data, search, permission, latency and observability problem.
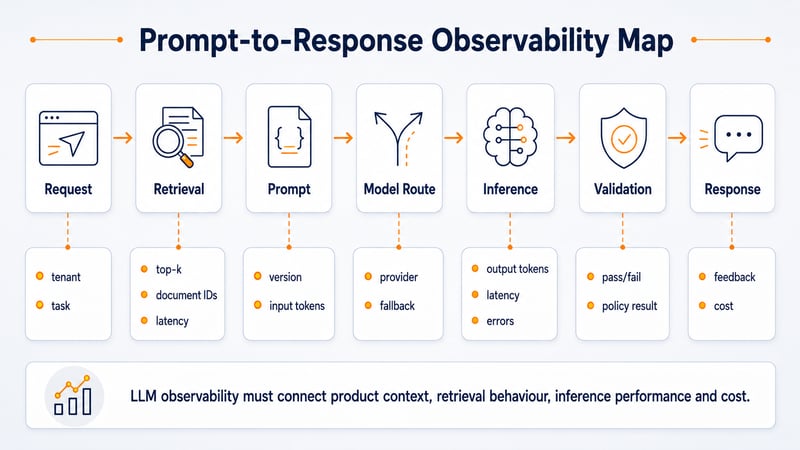
4. Observability Stops at Logs and Infrastructure Metrics
Traditional observability is not enough for LLM systems.
A standard dashboard may show API latency, error rate, CPU, memory, pod restarts and log volume. Those metrics still matter, but they do not explain why an LLM response was poor, expensive, slow, unsafe or inconsistent.
Production LLM observability needs visibility across the full prompt-to-response lifecycle.
This is where OpenTelemetry GenAI semantic conventions become useful, because they define AI-specific telemetry such as request duration, token usage, time to first token and time per output token.
OpenTelemetry also defines GenAI attributes for provider, model, operation, request and response context, helping teams connect AI-specific behaviour to the wider telemetry model.
That means connecting:
-
user and tenant context
-
task type
-
retrieval decision
-
retrieved documents
-
prompt version
-
model route
-
input and output tokens
-
latency
-
retries
-
fallback path
-
guardrail result
-
validation result
-
cost per request
-
user feedback
Without this, teams can see that something went wrong, but not where the failure was introduced.
-
A weak answer may be caused by retrieval.
-
A slow answer may be caused by queueing.
-
A high-cost answer may be caused by unnecessary context.
-
A failed request may be caused by throttling.
-
A compliance issue may be caused by missing policy enforcement.
If these signals are not connected, debugging becomes guesswork. This is also why observability for DevOps teams needs to evolve when AI workloads become part of production systems.
Minimum useful observability model
|
Layer |
What to observe |
|---|---|
|
Product |
Tenant, user journey, task type |
|
Retrieval |
Query, filters, top-k, document IDs |
|
Prompt |
Prompt version, input tokens, context size |
|
Inference |
Model, route, latency, output tokens |
|
Reliability |
Errors, retries, throttles, fallback usage |
|
Governance |
Guardrail result, redaction, validation |
|
Cost |
Cost per tenant, feature and workflow |
LLM observability should explain not only whether a request failed, but why the answer, cost, latency or behaviour changed.
5. Governance Is Added Too Late
Security in LLM systems is often discussed in terms of prompt injection, data leakage and guardrails.
Those risks matter.
But production governance is broader than adding a guardrail after the model call.
A production LLM platform needs control over:
-
who can call which AI capability
-
which tenant the request belongs to
-
which data sources can be used
-
which documents can be retrieved
-
which model routes are allowed
-
which prompts can be used
-
what can be logged
-
what must be redacted
-
which responses require validation
-
which workflows need audit trails
For Amazon Bedrock workloads, model invocation logging can support traceability, but logging policies should be designed carefully when prompts or responses may contain sensitive data.
This is especially important for SaaS, fintech, healthcare and regulated environments where LLM features interact with customer data, internal knowledge or business workflows.
Governance should be part of the request path.
Not a policy document outside the architecture.
Production governance controls
|
Control |
Why it matters |
|---|---|
|
Tenant-aware routing |
Prevents cross-tenant policy mistakes |
|
Data access checks |
Prevents unauthorised context exposure |
|
Prompt redaction |
Reduces sensitive data entering the model path |
|
Response validation |
Prevents malformed or unsafe outputs |
|
Audit logging |
Supports investigation and compliance |
|
Token budgets |
Prevents uncontrolled usage |
|
Model allowlists |
Controls which models can be used for which tasks |
Guardrails are useful, but they are not the full governance model.
The stronger pattern is a governance control plane around the LLM request lifecycle.
A Short Production Readiness Check
Before scaling an LLM deployment, engineering teams should be able to answer these questions.
|
Area |
Key question |
|---|---|
|
Architecture |
Do product services call models directly, or is there a shared inference layer? |
|
Routing |
Are model routes selected by workload, tenant, latency and data sensitivity? |
|
Retrieval |
Can the team see which documents were used in each response? |
|
Latency |
Is end-to-end latency measured, not just model latency? |
|
Cost |
Are tokens tracked by tenant, feature and workflow? |
|
Security |
Is data access checked before retrieval? |
|
Observability |
Can engineers trace a request from user action to model response? |
|
Governance |
Are prompts, logs, responses and model routes controlled? |
If the answer to many of these questions is unclear, the LLM feature may work, but the platform is not yet production-ready.
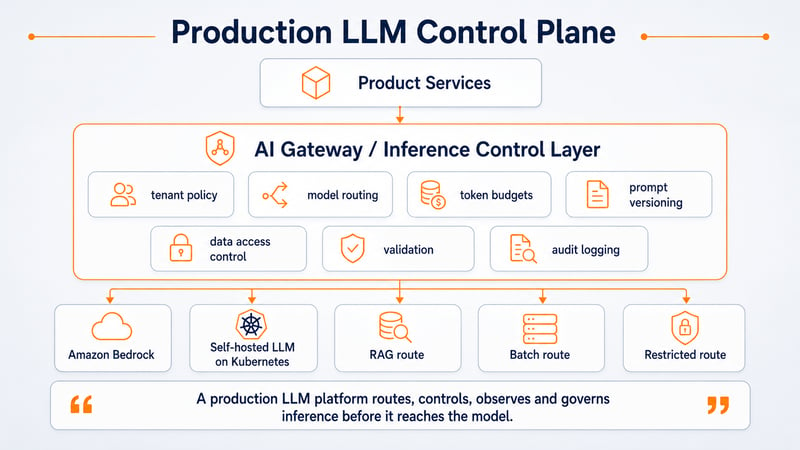
What a More Reliable LLM Production Architecture Looks Like
A more reliable LLM architecture separates responsibilities clearly.
Product services
↓
AI gateway / inference control layer
↓
Policy, routing and budget controls
↓
Retrieval and RAG pipelines
↓
Prompt assembly and versioning
↓
Model routes
→ Amazon Bedrock
→ Self-hosted LLM on Kubernetes
→ Batch inference
→ Restricted workflow route
↓
Guardrails and validation
↓
Observability and cost attribution
↓
Product responseFor self-hosted LLMs on Kubernetes, runtime operations need more than standard service routing and CPU-based autoscaling. CNCF discussions around the Gateway API Inference Extension and KEDA-based GPU autoscaling show how inference platforms are moving toward metrics-aware routing and GPU-aware scaling.
The goal is not to make the system unnecessarily complex.
The goal is to stop hidden complexity from spreading across the product.
Production LLM systems need clear ownership of model access, retrieval, routing, security, observability, cost and runtime operations. For teams running AI workloads on Kubernetes, this often requires the same operational discipline used across Kubernetes consulting services, platform engineering and production reliability work.
Once those responsibilities are separated, teams can improve the platform without rewriting every AI feature.
Where Bion Helps
Most LLM production problems are not isolated model problems.
They are platform architecture problems.
A working prototype may prove the product idea, but production requires a stronger foundation: controlled model access, reliable retrieval, secure data flows, cost-aware routing, runtime observability and operational ownership across AWS and Kubernetes environments.
Bion helps teams design and implement production-ready AI platforms on AWS, including Generative AI and LLM deployment, RAG architecture, Amazon Bedrock integration, Kubernetes-based inference workloads, observability, cost control and AI Platform Operations and MLOps on AWS.
For teams moving beyond prototype stage, the key question is not only:
Which model should we use?
It is:
Can our platform operate this AI capability reliably, securely and cost-effectively in production?
If your AI product is starting to face latency, cost, observability, routing or governance challenges, Bion can help you review the architecture and define the production controls needed before those issues scale further.
Book a technical strategy call to review your AWS LLM architecture and production readiness.